
Ab wann sind Daten groß genug um Big genannt zu werden? Und ist Big nicht ein wenig relativ und willkürlich?
Zuerst einmal stellt sich die Frage, was Daten überhaupt sind. Schon hier wird es schwammig, denn eine allgemein gültige Definition gibt es nicht. Aber für unsere Zwecke reicht es, wenn wir uns darauf einigen, dass Daten Angaben oder (Zahlen-)Werte sind, die durch Messung oder Beobachtung gewonnen werden. Um die Frage nach Big Data zu beantworten, schadet es nicht ein wenig auszuholen.
In dem Fall ist „ein wenig“ etwa 20.000 Jahre. Aus dieser Zeit (also ca. 18.000 v.Chr.) stammt das älteste uns bekannte Kerbholz, der Ishango-Knochen. Natürlich war niemand dabei der heute bestätigen kann, dass die Gravuren auf diesem Knochen tatsächlich dazu angebracht wurden um zu „zählen“. Aber die Vermutung steht im Raum und ist nicht ganz unbegründet. In dem Fall wurde mit diesem „Werkzeug“ die menschliche Kapazität, Zahlen (also Daten) zu speichern, erweitert.

Um das Jahr 2.000 v.Chr. wurde der Abakus erfunden (der oft mit dem Rechenschieber verwechselt wird). Somit stand der Menschheit ein Werkzeug zu Verfügung um nicht nur die (menschliche) Speicherkapazität für Zahlen zu erhöhen, sondern auch die Rechen- also Verarbeitungskapazität. Etwa 300 v.Chr. entstand die Bibliothek von Alexandria die symbolisch für die groß angelegte Speicherung eines neuen Datentyps steht: die (Hand-)Schrift mit der Text(-Daten) festgehalten werden können.
Danach tut sich datentechnisch relativ lange eher wenig. Interessant wird es ab 1662 (n.Chr.). In dem Jahr publiziert John Graunt die ersten Sterbetafeln und altersabhängige Überlebenswahrscheinlichkeiten. Damit begründet er die Demographie und gilt als Wegbereiter der modernen Statistik. Erst dank dieser Methoden wird es zukünftig möglich aus Daten neue Erkenntnisse (Information) zu gewinnen. Eine Entwicklung die rasch an Fahrt gewinnt. Denn nur 200 Jahre später stößt man damit schon an Grenzen. Die Auswertung der US Volkszählung von 1880 dauerte geschlagene acht Jahre. Da bereits zwei Jahre später, also 1890, die nächste Volkszählung ansteht (mit noch mehr erhobenen Daten, alleine durch das Bevölkerungsplus von 25%), wird befürchtet, dass die Ergebnisse nicht vor der übernächsten fertig werden.

Auftritt Herman Hollerith. Rund um die Idee Daten binär (Loch oder kein Loch) auf einer (Papier-)Karte zu speichern, entwickelt er eine elektromechanische Maschine um Daten zu verarbeiten. Dank ihr kann die Volkszählung deutlich schneller ausgewertet werden (je nach Quelle in 4 Monaten, 2 Jahren oder 6 Jahren). Somit wird erstmals Strom genutzt um Daten zu verarbeiten. Hollerith macht seine Zählmaschinen zum Geschäft. Er verkauft sie jedoch nicht, sondern vermietet sie weltweit (neben den USA u.a. an Kuba, Kanada, die Philippinen, Russland und Österreich) für die Auswertung von Volkszählungen. Seine Firma wird nach Verkauf und Umbenennung später als IBM bekannt.
Das 19.Jahrhundert ist datentechnisch generell ein interessantes. In der ersten Hälfte wird die Fotografie entwickelt, die es ermöglicht Bilder „naturgetreu“ zu speichern und ab 1877 werden Tonaufnahmen möglich. Videoaufnahmen gesellen sich dann ab 1930 dazu. Und dann wird es wirklich interessant, denn ab 1930 ist es möglich Information auf Magnetbändern zu speichern und in den 1940ern werden die Grundlagen des heutigen Computers entwickelt.
In der weiteren Folge entwickelt sich die weltweite Informationsmenge rasant. Im Jahr 1944 publiziert Fremont Rider eine Untersuchung Amerikanischer Universitätsbibliotheken. Er kommt darin zum Schluss, dass sich deren Volumen alle 16 Jahre verdoppelt. Der Bibliothek in Yale sagt er, bei diesem Wachstum, für 2040 eine Regallänge von knapp 10.000km voraus, sowie 6.000 Angestellte für die Katalogisierung.
1975 gibt das Japanische Post und Telekommunikationsministeriums eine Studie in Auftrag die belegt, dass die Menge an zur Verfügung gestellter Information weitaus schneller wächst als jene die konsumiert wird. Damit erfolgt der erste empirische Beweis für den Begriff „Information Overload“. Diese Information ist nach wie vor analog gespeichert, das ändert sich aber ab den 1990ern dramatisch. Sind 1986 noch 99% der Information analog gespeichert, so sind es 2007, nur 20 Jahre später, bereits 94% digital (Quelle hier).
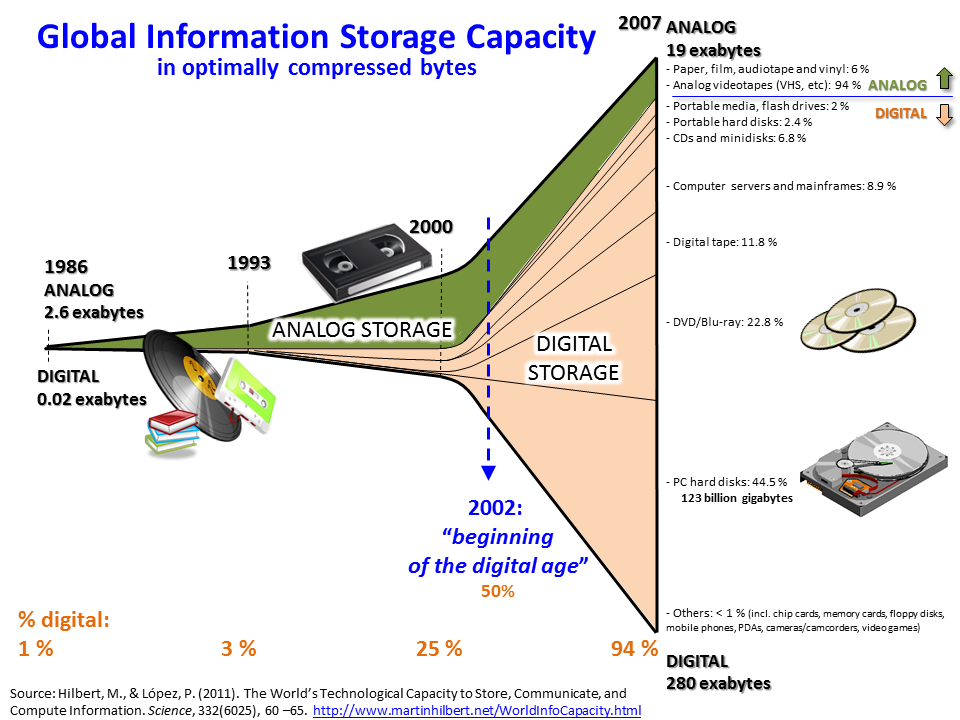
Bild zur Verfügung gestellt von Myworkforwiki unter CC-By-SA Lizenz.
Big Data als Begriff wird um etwa 2000 geprägt – drei Jahre nachdem Google aus der Taufe gehoben ist. 2007 erleben Smartphones ihren Durchbruch und spätestens ein Jahr danach ist Big Data als Buzzword omnipräsent. Doch was genau charakterisiert das Big in Big Data eigentlich? Wenngleich es (auch hier) keine einheitliche, allgemeine Definition gibt, so kann man sich doch auf drei Vs einigen: Volume, Velocity, Variety. Also ein großes Datenvolumen, eine hohe Geschwindigkeit betreffend die Generierung und den Transfer von Daten, sowie eine große Bandbreite an Datenquellen und -Typen.
Es gibt jedoch noch zwei interessante V‘s. Nämlich Value und Veracity, also Wert und Authentizität. Und erst dadurch wird Big Data interessant. Denn ohne die Möglichkeit verlässlichen Mehrwert (also Information) aus den gespeicherten Daten (Beobachtungen) zu gewinnen, ist die Sammlung von Daten uninteressant. Oder anders formuliert: Erst wenn man die Kerben auf dem Kerbholz zusammenzählen und auswerten kann, wird aus den Kerben (gespeicherte Daten) eine relevante Information: die Summe. Und genau so, wie die Technik in der Geschichte immer wieder an ihre Grenzen gestoßen ist, stößt die herkömmliche (Computer-)Technik bei Big Data an ihre Grenzen.
Um immer mehr und komplexere Berechnungen durchzuführen brauchte es den Abakus. Mit dem Aufkommen von Volkszählungen wurde es notwendig statistische Methoden zu entwickeln und das sukzessive Mehr an Daten wurde erst durch den Computer und die EDV bewältigbar. Durch die Weiterentwicklung der Technik, konnten mehr Daten verarbeitet und mehr Information daraus gewonnen werden. Daher war es naheliegend, dass auch mehr Daten gesammelt und erhoben werden.
Dank der rasanten Verkleinerung und Verbilligungen von Computern, haben sie in den letzten 10-20 Jahren ziemlich jeden Lebensbereich durchdrungen. Die Handys, Fitnesstracker, Autos, smarten Geräte, autonomen Messsensoren, etc. sammeln dabei unentwegt Daten. Um daraus Information zu gewinnen müssen die Daten aber miteinander verknüpft und in Kontext gebracht werden. Dafür sind neue Techniken notwendig: Machine Learning und Künstliche Intelligenz (KI). Die Entwicklung in diesen Bereichen ist erst dank Big Data möglich, denn KI und Machine Learning brauchen riesige Datensätze um „trainiert“ zu werden. Umgekehrt können viele Erkenntnisse aus Big Data nur dank ihnen gewonnen werde. Und wie bei jeder neuen Technologie sind viele geneigt in KI den Heiligen Gral und die eierlegende Wollmilchsau zu sehen. Doch die Entwicklung steckt einerseits (noch) in den Kinderschuhen, zeigt andererseits aber auch sehr deutlich ihre Schattenseiten – was aber (mindestens) einen eigenen Artikel wert ist (ein sehr empfehlenswertes Buch dazu ist Weapons of Math Destruction).
Zusammenfassend kann getrost geschrieben werden, dass Big Data kein neues Phänomen ist. Und auch nicht die damit einhergehenden Herausforderungen. Die Menschheit hat schon immer danach getrachtet mehr Information zu gewinnen. Jetzt heißt das eben Big Data und Künstliche Intelligenz (KI). Klar ist, dass (Big) Data nicht verschwinden wird. Klar ist aber auch, dass wir noch viele Diskussionen über Ethik, Datenschutz und Privatsphäre werden führen müssen. Denn schlecht sind Daten per se nicht. Sie werden es erst durch Missbrauch oder einen sorg- und ahnungslosen Umgang.
Anm.: Titelbild wurde erstellt von Beamten des United States Census Bureau und ist daher in der Public Domain.
Ein Kommentar
Die Kommentare sind geschlossen.